
Accelerate Success with AI-Powered Test Automation – Smarter, Faster, Flawless
Start free trial



Software defects do not usually become expensive the moment they appear. They become expensive when teams realize too late that a failure should never have made it to release.
A good example is the CrowdStrike outage in 2024, where a defective update triggered widespread disruption across critical systems worldwide. It shows how quickly a release issue can turn into a much larger business problem. For engineering leaders, it brings up a familiar concern: even with extensive testing, it is not always easy to tell which failures need immediate attention.
That is where AI defect prediction becomes useful. For senior engineering management, software quality now reaches far beyond QA outcomes. It directly affects release confidence, engineering efficiency, and the cost of getting a decision wrong.
Much of the difficulty comes later, when teams have to decide what actually needs action.
Why Test Automation Alone Doesn’t Solve This Problem
Automation increases test activity, but not always decision clarity. As test suites grow, teams are left with more results to review, more failures to triage, and less certainty about what deserves attention first.
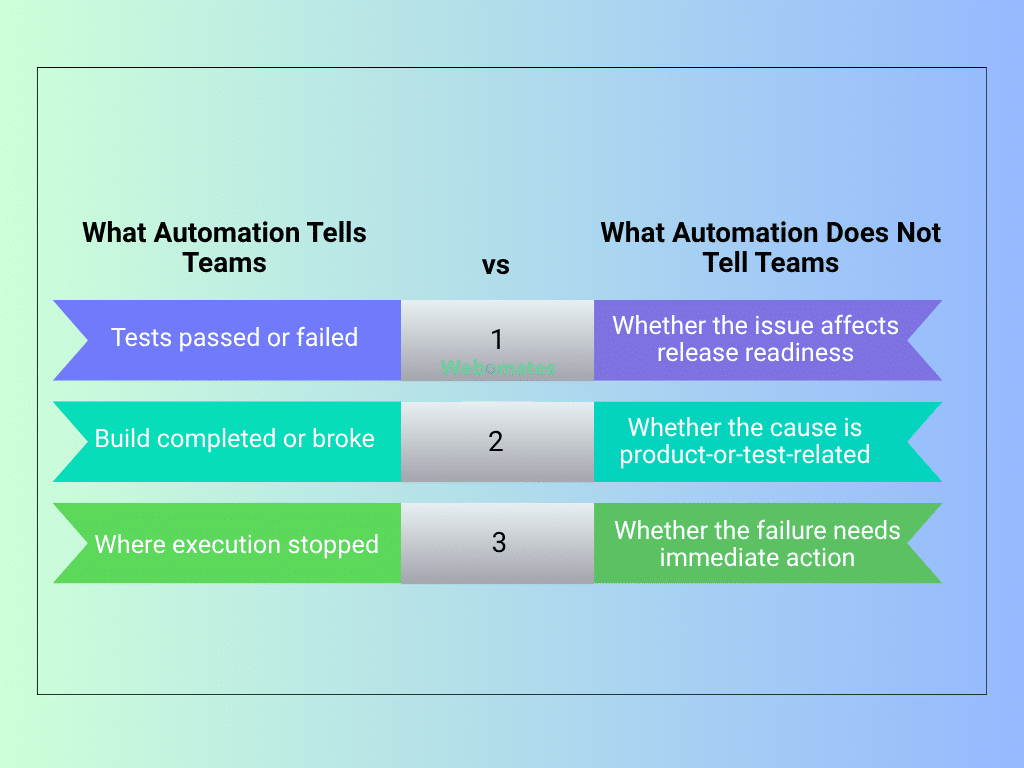
Teams can see what happened in execution, but they still need to determine whether a failure belongs in:
- Triage
- Rerun
- Escalation
As test volume expands, so does the effort required to interpret results.
How AI Defect Prediction Identifies High-Impact Failures
In most QA workflows, failed tests appear one after another, without enough context to show whether they are isolated events or signs of a deeper issue. That makes it difficult to know which failures are repeatedly affecting system stability and which ones are unlikely to influence release readiness.
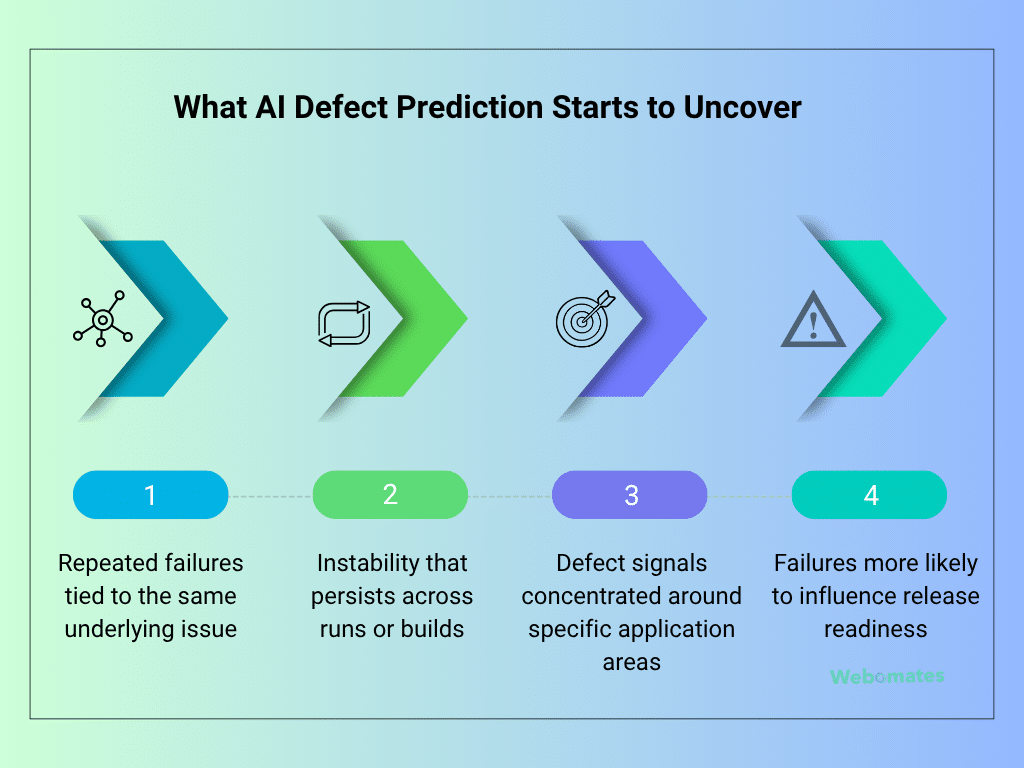
As those patterns become visible, teams can direct investigation effort toward the failures most likely to require action instead of treating every failed result with the same level of urgency. That visibility changes how teams investigate failures, prioritize engineering effort, and judge release readiness.
How Failure Analysis Changes in AI QA Testing
Most failure analysis slows down long before a defect is confirmed. The delay usually comes from the effort required to piece together evidence across logs, screenshots, runs, and execution reports before teams can decide whether a failure actually deserves action.
In a research analyzing more than 1 million test failures across 2,000 builds, machine learning–based failure classification was shown to save up to 20 minutes of computation time per build compared with relying on reruns alone.
Another empirical study found that 75% of flaky tests belonged to a cluster, showing that repeated failures are often connected to shared underlying causes rather than isolated incidents.
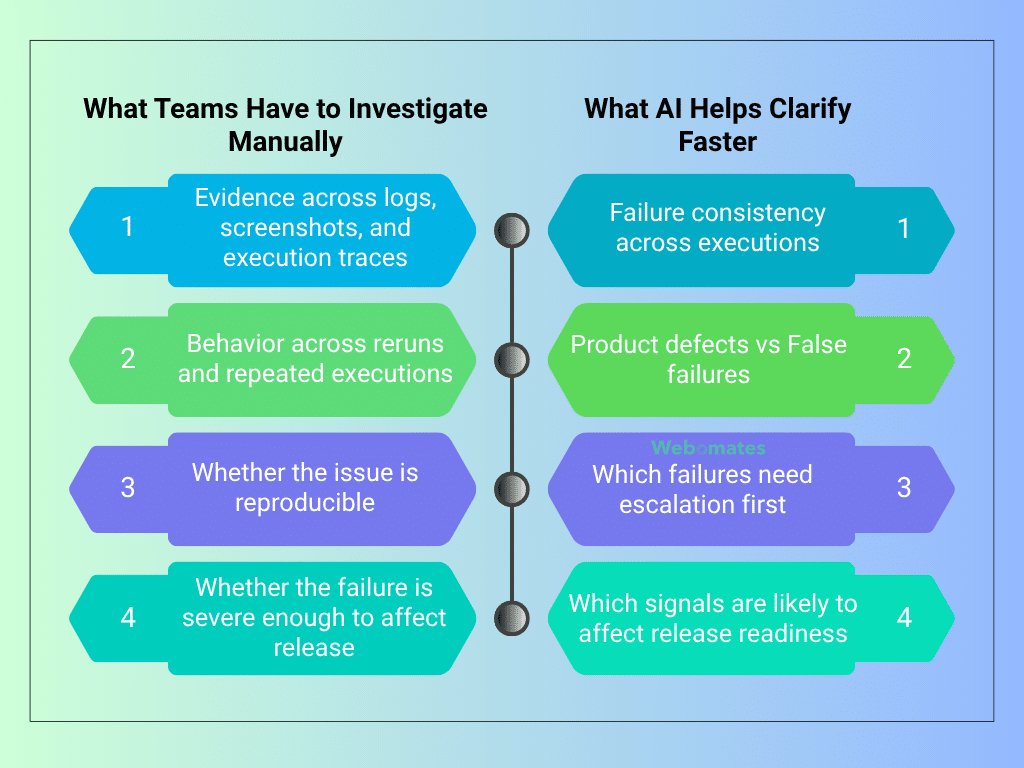
This is where AI quality assurance becomes more useful than raw test reporting. Instead of leaving teams to interpret disconnected outputs, it helps convert test failures into usable defect signals.
Platforms like Webomates apply this by combining test execution, failure analysis, and AI defect prediction into the same workflow. Each failure can be:
- Reviewed across multiple executions
- Evaluated for consistency and
- Supported with the context needed to determine whether it requires action
Webomates AI Defect Predictor is designed to reduce the time spent on failure triage by helping teams identify actionable failures faster and avoid repeated analysis of false or low-value outcomes.
Its patented AI capabilities also help eliminate redundant or low-value test cases, keeping your testing focused on higher-impact areas.
It can also provide:
- Details that help teams reproduce the issue
- Prioritization signals
- Execution Evidence
These make failures easier to evaluate and act on.
How Predictive QA with AI Improves Release Decisions
Predictive QA with AI gives release planning a stronger basis than test completion alone. It helps teams decide:
- What can move forward
- What needs more validation
- What should be escalated before release
This reduces:
- Unnecessary test cycles
- Delayed issue escalation
- Late-stage uncertainty
And improves:
- Delivery predictability
- Release readiness
For senior engineering management, that means release decisions rely less on last-minute judgment and more on visible risk signals.
When AI QA Testing Works—and When It Doesn’t
The effectiveness of AI QA testing depends on how consistently failure behavior is captured and connected across the testing workflow.
| When AI QA Testing Becomes Reliable | When it Becomes Less Reliable |
| Historical execution data is available across runs | New features have little or no prior execution history |
| Test, code, and failure signals are connected | Evidence is fragmented across disconnected tools |
| Execution outcomes are captured consistently over time | Failure behavior is recorded inconsistently or incompletely |
AI defect prediction depends on the ability to learn from these patterns. When failure signals are not captured consistently, prediction quality becomes harder to trust in release decisions.
What QA Teams No Longer Need to Do Manually
As AI in software QA becomes more effective at interpreting failure behavior, teams spend less time on work that adds effort without improving release decisions.
That includes:
This is one of the clearest operational benefits of AI quality assurance. It reduces manual effort not by removing QA judgment, but by reducing the amount of repetitive analysis required before teams can act.
Conclusion: The Shift Is Not Faster Testing—It’s Smarter Interpretation
Traditional QA tells teams what failed. AI defect prediction goes a step further by helping them understand what matters, what can wait, and what needs action first.
That is where Webomates AI Defect Predictor becomes relevant, by helping teams spend less time reviewing low-value failures and more time responding to issues that actually affect release decisions.
As Jeff Bezos put it, “Good intentions don’t work, mechanisms do.” That idea applies directly to AI in software QA: better release outcomes depend not just on test execution, but on having the right mechanism to interpret what the results actually mean.
From Reactive QA to Predictive Testing
Let AI predict defects, automate tests, and speed up your releases by 10X.
FAQs
1. Is AI defect prediction only useful for large engineering organizations?
No. It becomes useful anytime teams start losing too much time reviewing failures that do not lead to meaningful action. That can happen in large enterprises, mid-sized product companies, and fast-growing teams alike. The value usually shows up when the release pressure increases faster than the team’s ability to investigate every failed result manually.
2. How is AI defect prediction different from standard test reporting?
Standard reporting shows what passed and what failed. AI defect prediction is more useful when teams need help understanding which failures are likely to matter, which ones are likely to repeat, and which ones are unlikely to affect a release. That difference matters most when leadership needs faster, better-informed decisions rather than more raw output.
3. How does AI predict software bugs before they become release issues?
It usually comes down to pattern recognition. Systems learn from execution history, recurring failure behavior, rerun outcomes, and defect trends across builds. In other words, how AI predicts software bugs is less about guessing and more about identifying patterns that teams would otherwise take much longer to connect.
4. How can engineering teams reduce QA errors with AI without over-automating the process?
The best results usually come from improving interpretation, not removing human judgment. Teams that successfully reduce QA errors with AI tend to use it to improve consistency in triage, failure review, and defect analysis, while still keeping product and engineering decisions in human hands.

Ruchika Gupta, COO and Co-founder of Webomates, has 20+ years of experience in product delivery and global tech operations. She has held key roles at IBM, SeaChange, IPC Systems, Birlasoft, and served as President of Fonantrix Solutions. She writes about scaling operations, building strong delivery teams, and enabling smarter testing practices.
Tags: AI Defect Prediction, AI in Software Testing, est Automation with AI, Predictive QA Testing, Software Quality Assurance
Leave a Reply