
Accelerate Success with AI-Powered Test Automation – Smarter, Faster, Flawless
Start free trial
Using AI/ML in software testing accelerates the whole QA process and delivers accurate results saving thousands of man-hours. The following figure outlines how AI/ML is used to improvise software testing.
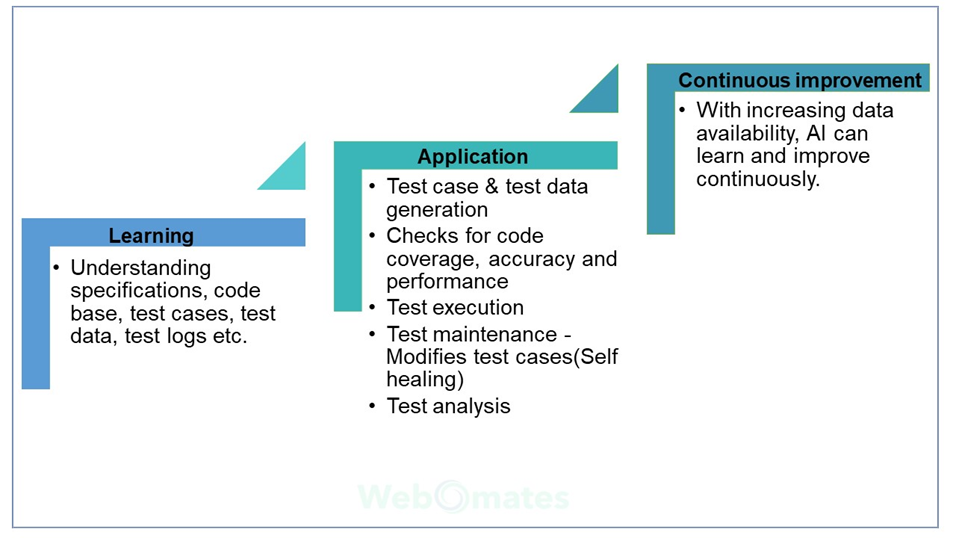
- Learning: It involves understanding the testing process, codebase, underlying algorithms, data bank, etc. to fully equip the AI tool with the knowledge to apply in the testing.
- Application: Once the AI tool is equipped with the knowledge, it can then apply its learnings for test generation, execution, maintenance, and test result analysis.
- Continuous improvement: It is the key to AI enhancement. As the AI tool usage grows, so does the data and scenarios at its disposal from which AI can learn and evolve, and consequently apply its knowledge to further improve the testing process.
In nutshell, AI application in its current state equips itself for predictions and decision-making based on the learnings from a set of predefined algorithms and available data.
One attribute that is common in all three activities is “data”. So, why is data so important?
The predictive analysis and decision-making capabilities of any AI/ML application are based on the learnings from a set of predefined algorithms and available data.
While algorithms are defined and designed by a team of experts, it is the data that brings unpredictability to the whole equation.
Why? Because of the sheer volume of available data, almost to the magnitude of several Yottabytes, which is a heterogeneous mixture of good, bad, and useless.
Any data that goes into AI/ML systems needs to be cleaned first. . I have discussed this in detail in my first article of the Data Model series – “AI Models in Software Testing – How to prepare data”.

The figure below is a pictorial representation of the processing cycle that data has to undergo before it is deemed worthy of use for any decision-making in AI/ML systems.
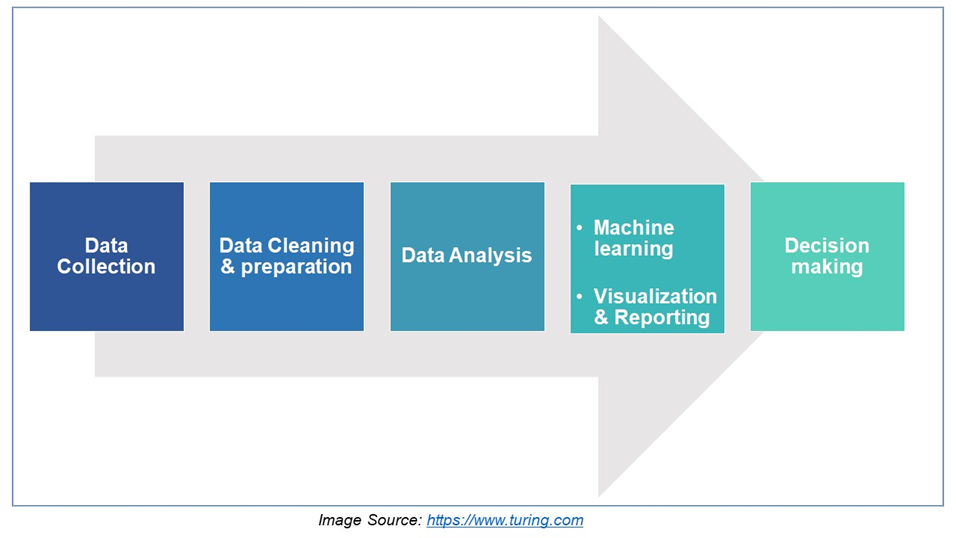
The very first step of any data-related activity is data collection.
Data collection is an extremely important activity because it forms the base of providing information pertinent to the AI Model.
It was not an easy activity for us to get the right data initially since we were doing it in an ad-hoc manner. It was an extremely boring task and we ended up making mistakes.
Let me list down how it was helpful in some ways (yes, it was), and what were the reasons that led us to conceptualize the Incidence viewer.
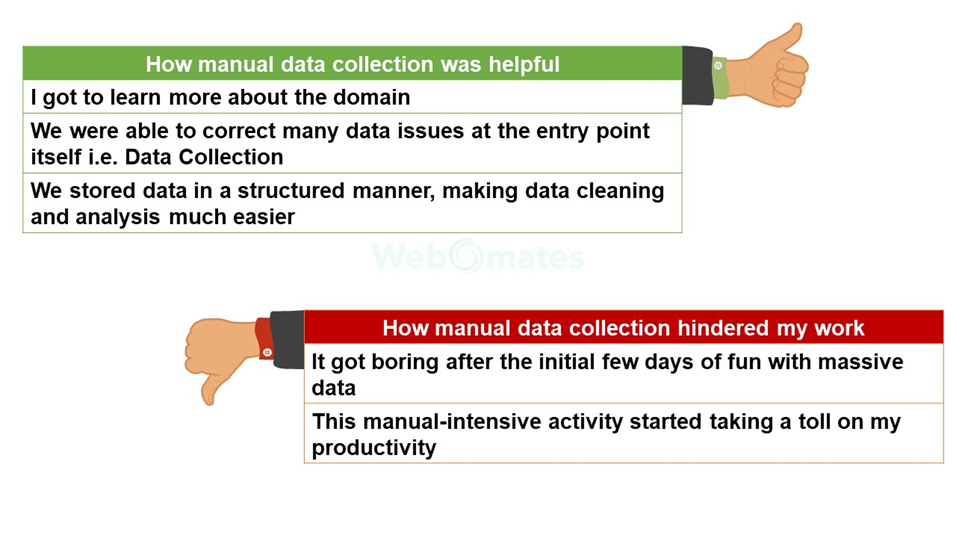
Let me list down how it was helpful in some ways (yes, it was), and what led us to conceptualize the Incidence viewer.
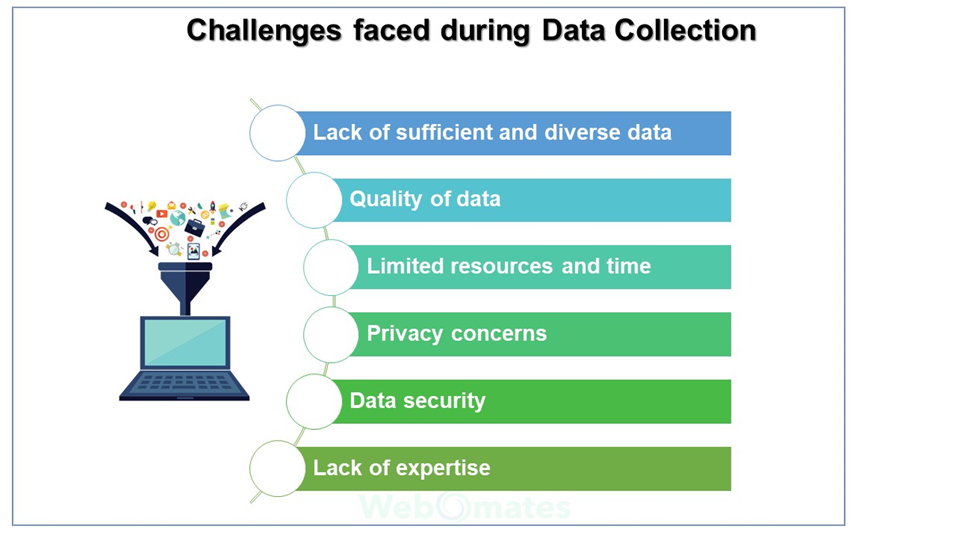
Quality of data: The quality of data is the key for the AI model to be accurate and effective. Inaccurate or incomplete data can lead to a biased model. Sifting through the data to determine its quality was a time-consuming task.
Limited time and resources: Collecting and labeling data for software testing can be very time-consuming, especially for larger datasets.
Privacy concerns: Collecting personal data can raise privacy concerns, so the focus was to gather the data from the open source or from the organization itself, which further posed other challenges like quality or security concerns.
Data security: Data security is critical, especially when dealing with sensitive user data. It was important to seek consent from the respective customers to use their data for training the model.
Lack of expertise: Data collection for AI models requires a significant level of expertise, including knowledge of data collection methodologies, data cleansing, and data preprocessing.
All these were taking a toll on productivity and progress was slow.[1]
The idea of having a handy tool for automated data collection was born out of sheer necessity to make data collection efficient. That’s when the Incidence Viewer came into the picture.

Let’s talk about Incidence viewer tool
As evident from the challenges listed in the previous section, data collection was getting taxing and repetitive in nature. I desperately needed a genie to handle mundane tasks, so I could work on other aspects of projects that tickled my brain cells.
The Incidence viewer tool was created to assist AI and data engineers in our team with data collection and classification, specifically for the software testing domain. It expedited the whole process and saved significant effort and time.
This tool was created with a strong focus on the elements that determine a feature change when a test case fails. It examines the key elements and their subcomponents that help in determining any feature change. Our algorithm then uses these elements to accurately determine the probability of feature change.
The Incidence tool evolved from being just a prototype to being an integral part of our everyday data collection operations. Our team has saved hundreds of man-hours with the usage of the incidence tool and our productivity went up.
The future holds promises to add more features to it. But as of now, I am happy that it has eased my burden and has given me the bandwidth to focus on other important tasks which helped me in my AI/ML journey.
If you liked this blog, then do leave a rating and share your comments and insights. Your opinions matter.
If my thoughts and experiences have intrigued you enough to know more about my company’s testing services then Click here to schedule a demo. You can also drop a message at info@webomates.com and someone from our team will reach out to you.
If you liked this blog, then please like/follow us Webomates
Read Next –
Agile requirements traceability matrix
Tags: AI Testing, Automation Testing, Autonomous testing, Intelligent automation, Test Automation
Leave a Reply