
Accelerate Success with AI-Powered Test Automation – Smarter, Faster, Flawless
Start free trial
What is Data?
Technically speaking, data can be defined as “Information that has been translated into a form that is efficient for movement or processing”. As of now, roughly 2.5 quintillion bytes of data are generated daily, but is that all useful?

Organizing, analyzing and extracting meaningful data is a necessary exercise that reaps benefits in the long term.
What is Data Preparation for AI Models?
In simple terms, “Data Preparation is the process of gathering, cleaning, and transforming the data.”
The objective of the data preparation process is the reconstruction of raw data in such a way that it can run through a machine learning algorithm to provide us insights or uncover a business problem at hand.
Data preparation is a very crucial and undoubtedly the most tedious task in the whole AI model building cycle. 80% of the time goes into Data preparation for building AI models for software testing.

Why is data preparation so important?
Raw data is unadulterated data that needs to be processed before it can be used as meaningful information.
Raw data cannot be used in its original form since it often consists of missing and invalid values which can make the AI model behave unpredictably. Hence, it is important to “clean” the data before using it because the performance of any AI/ML model heavily depends on its data preparation process.

Significance, complications, and steps involved in the Data Preparation stage
Data preparation is the key activity when it comes to setting the stage for data analysis for an efficient AI model. However, it is not that easy and requires quite a lot of research.
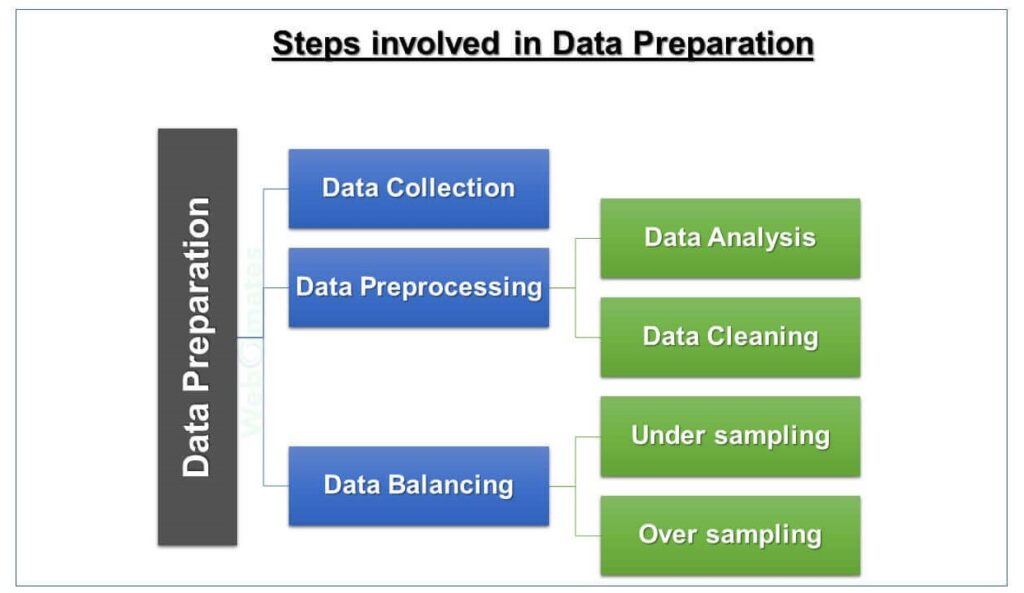
1. Data Collection: Setting the base for AI model
Data collection has always been a tedious process. While other domains need specific data for developing their AI/ML model, such as numbers or images, it is complicated when developing an AI/ML model for software testing because testing data is not restricted to a specific kind, and is in the form of network logs, browser logs, images, HTML files, numbers, and texts. Precisely the reason why a robust AI/ML model in the software testing domain has not been released yet.
Let us take a quick look at the problems that I encountered during data collection and the solution that helped me immensely.
| Roadblocks | Solution |
The image data was biased. It means that the data which indicates a non-feature change image of a webpage was much more as compared to the feature change image data. Another was a security and legal issue because it is not ideal to gather the data from random websites owing to security and privacy policies. | To get rid of security issues, we just need to be extra careful while collecting data, to eliminate any security threats. Getting customers’ consent was important before using their data for developing the model to bypass any legal issues that can arise in the future. |
2. Data Preprocessing: Core of the model
Data preprocessing is the core of our AI/ML model since the data quality is defined in this step. It is a time-consuming task because each kind of data gathered for building a model in software testing poses different problems and thus demands separate preprocessing ways.
I have described two important stages in data preprocessing below.
- Data analysis
Data analysis is the stage where the detailed examination of data is done. At this stage, we analyze gathered data and get the counts of missing values, incomplete values, number of duplicates, etc. The process itself is tough and has certain hurdles.
| Roadblock(s) | Solution |
| Data in software testing includes but is not limited to browser logs, network logs, HTML files, and images. In software testing, It is generally harder to analyze web page network logs, as network logs are vast and they require many transformations to get to the log part where our test case failed. | The use of Exploratory Data Analysis (EDA) techniques made this process faster. EDA is nothing but the use of statistics and visualizations of the data, which makes analysis easier and faster. |
- Data cleaning
Raw and garbage data pose lots of difficulties for the AI model.
Data cleaning refers to the process of fixing the problem of duplicate data, incomplete data, missing data, and invalid data. Sifting through garbage is never easy.
| Roadblock(s) | Solution |
| In software testing for web applications, duplicate image data was the most recurring problem. It takes time for the developers to make modifications in web applications. That means that a newer version release which reflects the changes is not that frequent. So the image data remained unchanged for quite some time before it got updated. Once done, we ended up having duplicate image data. | More patience in cleaning the data and consistency in analyzing the data regularly is the only way out for such problems |
3. Data balancing – Increasing AI model efficiency
Data balancing is a crucial part of data preparation in software testing because the data gathered is mostly imbalanced, i.e is not evenly distributed.
Data balancing is the process where certain techniques are used to make raw data evenly distributed considering all desired categories, features, etc.
There are various methods for balancing the data but the preferred ones are undersampling and oversampling.
- Undersampling
In undersampling, the training example of the majority class is reduced so that the classes are evenly distributed. Usually, this process makes the AI model train faster as fewer examples are present. But this also reduces model accuracy on the unseen data, that is, the trained model performs well on training data but performs poorly on unseen data, which is also called “Overfitting”.
- Oversampling
In oversampling, the training examples of minority classes are increased so that they are equally balanced. This does not make the model train faster, unlike undersampling. In Oversampling we use certain techniques to increase the training examples of minority classes. Oversampling is generally preferred over undersampling, as undersampling leads to data loss.
What made my software testing data preparation stage complicated?
Despite using good data preparation techniques, it is still a complicated task.
I faced several issues that made this stage difficult and time-consuming, as stated below

- Irrelevant data
- Irrelevant data is useless and just increases the cleaning process time. Also, the AI model will produce undesirable results and in some scenarios, it even fails to train.
- Duplicate data
- Duplicate data is the most common problem I encountered. It just increases the dataset size without having any significant impact on the end results.
- Missing values
- Missing values are also among the recurring issues. Missing values will result in an error during model training because the model cannot predict what the missing value is before it is trained.
- Incorrect data type
- Each piece of data has a specific data type, an alteration that can make the model stop during training. This problem arises mainly due to human-level errors.
Conclusion
Data preparation cannot be completed in a short time. But using the latest available methods to handle the data preparation process saved me a lot of time.
Understanding business needs while data preparation not only saved my precious time but also made the whole process extremely effective.
Knowing your data, i.e having software testing domain knowledge boosts overall process time. But the real key to success was the way we moved from ad hoc collection to manual structured collection to semi-automated data collection. But that’s the subject of my next blog!!!
If you liked this blog, then leave a rating and do share your comments and insights. And of course, check my company’s testing as a service offering at www.webomates.com so they keep paying me to have fun in the AI world.
If our services interest you then Click here to schedule a demo. You can also reach out to us at info@webomates.com.
If you liked this blog, then please like/follow us Webomates
Tags: AI, AI Model, AI Testing, Artificial Intelligence, Data Analysis, Data preparation
Leave a Reply