
Accelerate Success with AI-Powered Test Automation – Smarter, Faster, Flawless
Start free trial
In healthcare, there’s absolutely no room for error. When data is wrong or incomplete, the costs escalate quickly. Misaligned medical and drug benefits not only delay care but also increase administrative costs and payer/provider friction. Even small errors in healthcare data can have big consequences, both financially and in terms of patient safety.
Gartner estimates that poor data quality costs organizations $12.9 million per year. However, in the case of healthcare, these errors aren’t just costly; they’re dangerous too.
According to Healthwatch England, one in four patients has found errors in their medical records, which led to missed tests, incorrect prescriptions, and delayed treatments. In some cases, official medical records even listed illnesses patients never had. These mistakes can have fatal consequences, from dangerous delays to misdiagnoses and missed care.
That’s the seriousness of healthcare data– even a single small error can cascade into life-threatening outcomes. And when you consider the scale and complexity of today’s healthcare systems, the challenge of achieving zero room for error becomes clear.
The Scale and Complexity of Healthcare Data
The healthcare industry deals with some of the largest and most complex datasets. Its data integration market (including ETL tools) will expand from $2.4 billion in 2024 to $5.19 billion by 2029, reflecting rampant growth in data volumes and complexity.
Healthcare IT systems funnel data from EHRs, lab systems, insurance claims, and wearable devices—often hundreds of sources per provider. Each source has its own format, speed, and unique variations, and all these should be handled flawlessly.
Apart from accuracy, these systems should also comply strictly with privacy laws like HIPAA and global data regulations. Even the smallest violation or data mismatch can cost millions, incur regulatory penalties, and most importantly, disrupt patient care.
The combination of all these factors is what makes the healthcare data pipelines very sensitive. To manage this complexity, these providers depend on ETL (Extract, Transform, Load) pipelines to move and prepare data. However, if these pipelines aren’t tested rigorously, even small gaps can turn into costly and dangerous failures.
How ETL Breaks Healthcare (Human + Technical)
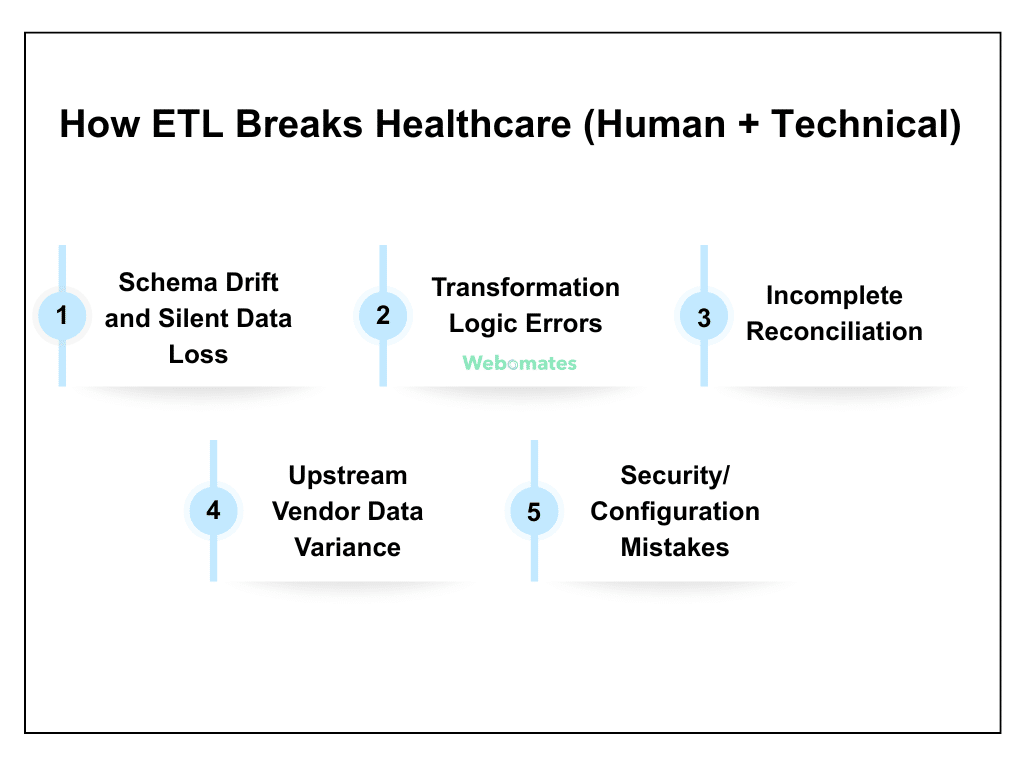
Even though ETL pipelines can handle massive amounts of healthcare data, they can also break in ways that can impact patient safety, compliance, and everyday operations.
Hence, the challenge here is not just limited to moving data, but ensuring that it remains accurate, consistent, and secure across hundreds of interconnected systems. Here are a few of the common failure modes, with examples.
- Schema Drift and Silent Data Loss: When EHR (Electronic Health Record) vendors add new fields or update formats, important values can sometimes be missed. Let’s say you are adding a new allergy field. If it isn’t mapped properly, the data may never reach the central system. What happens next? The doctors remain unaware of a patient’s critical allergy information, leading to unwanted risks. This is why ETL testing for healthcare data integrity is essential.
- Transformation Logic Errors: Sometimes, your rules for managing and standardizing data can cause unexpected problems. For example, a lab result meant for one patient might accidentally get linked to another if their unique identifiers get mixed up during data normalization. These mistakes can easily go undetected, putting patient safety and treatment at serious risk.
- Incomplete Reconciliation: In some cases, the number of records between systems may match accurately, but the data inside those records may differ. Let’s say a lab system sends 1,000 test results to the central system, and the row count matches. Yet a few results may be linked to the wrong patient, or some values may be formatted incorrectly. You have to ensure that there are no such mismatches that may lead to errors, thereby affecting patient care.
- Upstream Vendor Data Variance: Not all vendors will maintain the same data format. Multiple external vendors, such as labs, imaging centers, or insurance providers, may use different formats, timing, or quality. These inconsistencies can cause errors in patient records if ETL pipelines don’t carefully check and align all incoming data.
- Security/Configuration Mistakes: Even small misconfigurations or weak security settings can expose sensitive healthcare data or prevent it from reaching the right system. For example, improper permission settings might make certain lab results inaccessible to doctors, or a wrong configuration could allow unauthorized access. With careful ETL testing, you can ensure that data flows securely, reaches the correct destination, and remains secure.
Why Traditional ETL Testing (Manual + Scripted) Falls Short?
Healthcare data pipelines are very complex. Validating them manually is not an easy task. They are not only time-consuming but also prone to errors. In cases where you have to deal with millions of records coming in from EHRs, lab systems, and insurance claims, manual validation becomes nearly impossible.
Automation does exist, but it’s limited. Scripted SQL checks handle basics like row counts, null checks, and schema validation. However, when it comes to complex healthcare pipelines, these methods are insufficient. As your data volumes increase and regulations become more stringent, relying only on manual and scripted approaches may lead to errors, compliance risks, and operational challenges.
Limitations of Traditional ETL Testing
Even with manual validations and basic automation in place, traditional methods can’t keep pace with complex healthcare data. Here are a few of their limitations:
- Struggles with Semantic Accuracy: Traditional scripts can confirm the existence of data, but they often fail to detect deeper mismatches. Let’s say a patient is linked to the wrong procedure. Such an error can compromise patient safety, resulting in incorrect treatments.
- Brittle Systems: Each time a schema changes, be it a new field, a format update, or a vendor update, you have to rewrite the existing scripts for proper functioning. This slows down the testing process, and errors can slip through unnoticed during this transition.
- Blind to Data Drift and Anomalies: Traditional ETL checks focus on static rules. So, they don’t immediately spot the subtle changes or unusual patterns in the input data. Hence, without continuous monitoring, these errors might be identified only after they’ve caused issues in clinical or operational workflows.
- Batch Only Checks: Most scripted tests run only in batches. This means that the data will be checked only after it has already moved through the system. By the time the batch runs and flags issues, the incorrect information may already be in use, thereby affecting patient care, billing, or compliance.
- Insufficient Audit Trails for Compliance: Manual and scripted checks don’t maintain a complete log of the testing history. Without these detailed records, you may find it difficult to prove that you have complied with the regulatory requirements, resulting in audits and penalties.
How AI Shrinks Errors to Zero in ETL Testing?
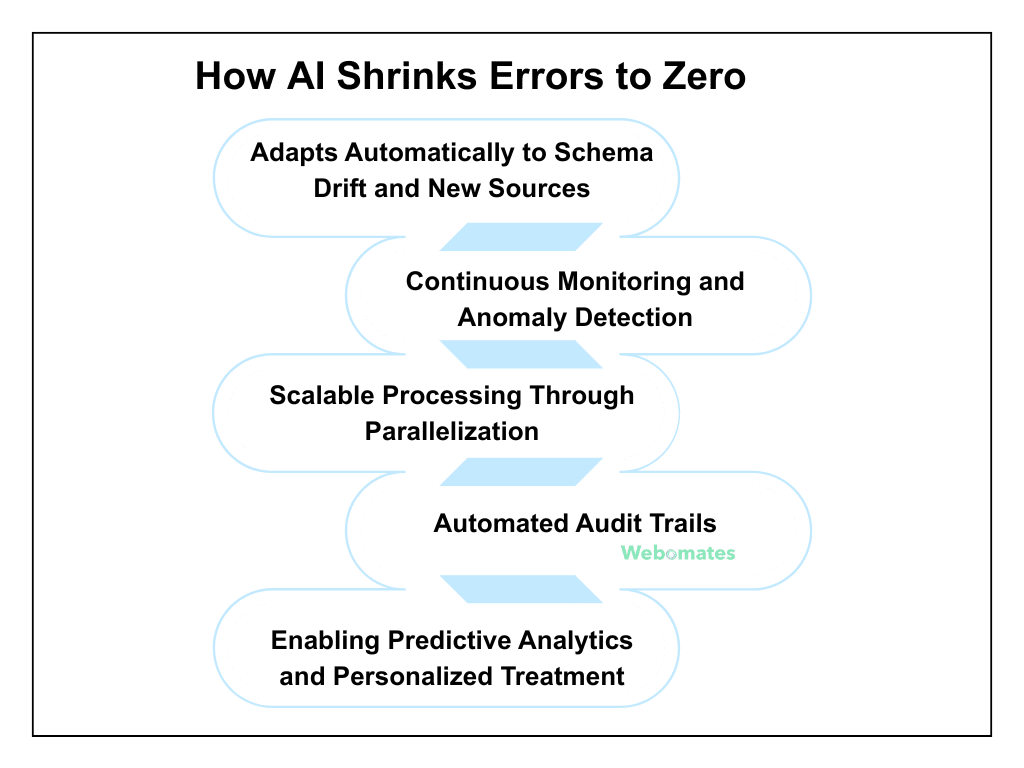
AI helps you to safeguard your complex healthcare data pipelines when used appropriately. It continuously learns from the input data and can identify issues immediately before they impact patient care, compliance, or operations.
It adapts to new sources, monitors data, and helps you make informed decisions, which may not be possible with traditional or automated checks. Here are some of its key features:
- Adapts Automatically to Schema Drift and New Sources: AI-driven ETL testing healthcare helps you to adjust pipelines when there is a change in data format or EHR fields, thereby reducing the risk of missing critical patient information.
- Continuous Monitoring and Anomaly Detection: AI anomaly detection in healthcare ETL workflows continuously checks datasets for any unusual patterns or potential risk records. It flags these issues, if found, and ensures smooth operations and patient care are provided.
- Scalable Processing Through Parallelization: Healthcare networks generate massive datasets that may slow down processing. AI ETL validation healthcare pipelines ensure that data flows smoothly and accurately, even when volumes are huge, thereby keeping operations unaffected.
- Automated Audit Trails: AI-enhanced ETL testing for healthcare analytics helps create complete logs of testing history automatically. This ensures you meet regulatory requirements and create accurate reports for auditors and administrators without any extra manual efforts.
- Enabling Predictive Analytics and Personalized Treatment: AI allows you to perform predictive analysis at the patient level, receive risk alerts, and provide personalized treatments based on these. This helps in improving patient care greatly.
Conclusion
Even with AI monitoring, test coverage, and sequencing for complex ETL chains are a bottleneck. Catching subtle errors across massive datasets is not so easy.
This is where Webomates comes into the picture.
It has successfully helped a large UK-based client in managing its complex ETL pipelines by using Generative AI to:
- Automatically create ETL test cases from huge datasets and complex, large files.
- Using intelligent queuing and chaining to manage large test cases.
Try Webo.Ai for a free trial, or contact us at info@webomates.com.
FAQs
When small teams work fast and release updates often, even a tiny code change can break something that was working fine before. Regression testing helps catch those issues early, keeping the product stable and reliable for users.
With limited time and resources, running all those tests can feel overwhelming. Webomates makes this easier by offering different regression options— smoke, overnight, full, and security— so teams can choose what best fits their needs. It also automates most of the heavy lifting, making testing faster and easier without slowing down releases.
For startups, time and resources are often tight— every release needs to be quick, reliable, and efficient. AI regression testing helps by automating repetitive test cases, identifying defects faster, and reducing the time spent on manual checks.
It can also spot patterns in bugs and predict areas that are most likely to fail, so that teams can focus their efforts in areas where it matters the most. Simply put, AI makes regression testing smarter and faster, helping startups maintain quality and scale without adding heavy QA overhead.
Webomates extends these benefits even further. It combines AI with automation and human validation to cover everything from quick smoke tests to full or overnight regressions. Its AI models can create new test scenarios, generate data, and even adapt test scripts automatically when the application changes. This helps reduce maintenance work that often slows down small teams. For startups trying to balance speed with reliability, this kind of approach helps keep testing consistent and release cycles smooth, without needing a large QA setup.
Choosing the best regression testing tool depends on what you need most— speed, coverage, or ease of use. Webomates helps teams reduce manual effort by combining automation with AI and human review.
This allows smaller teams to manage testing without spending too much time on setup or script maintenance. Ultimately, the best tool is the one that fits your workflow, provides quick feedback, and helps maintain quality while moving fast.
Small teams often struggle to balance speed and quality. Regression testing can be time-consuming, and with limited resources, it’s hard to run thorough checks after every change. Maintaining test scripts, managing flaky tests, and keeping up with frequent updates can quickly eat into development time.
Another common challenge is prioritization— deciding what to test and what to skip when deadlines are tight. Without a dedicated QA team, small teams risk missing hidden bugs or introducing new ones during quick releases.
Webomates help overcome these hurdles with AI-driven regression testing. Instead of spending hours maintaining scripts or rerunning old tests, it helps teams to focus on reviewing results and improving test coverage.
Aseem, Founder & CEO of Webomates, created Webomates CQ, an AI-driven testing platform that cuts testing time by 10x with AiGenerate , and accelerates test maintenance by 10x using AiHealing, with guaranteed 24-hour execution. A multi-technical Emmy award winner with AI automation patents, he writes about AI-first testing and faster, simpler software delivery.
Tags: AI in ETL Testing, ETL Testing, ETL Testing in Healthcare
Leave a Reply